
De nombreuses informations sont contenues dans des données dites « non-structurées », c’est-à-dire qui ne sont pas organisées (comme des textes, des images, des vidéos etc..).
Ces informations constituent une grande partie des informations dans les entreprises, c’est pour cette raison que les exploiter s’avère essentiel.
Note : Si vous avez lu que ces informations constituent plus de 80% des données des entreprises, je vous conseille la lecture de cet article qui est super intéressant et qui déconstruit ce mythe très répandu!
Les tweets sont un bon exemple de données non-structurée textuelles et nous allons voir pas à pas comment extraire et analyser des informations issues de ceux-ci avec OpenRefine.
Disclaimer : ce que je vais présenter est ma façon de faire, je ne suis pas un pro de l’utilisation d’OpenRefine. S’il est possible de réaliser certaines opérations de façon plus simple, n’hésitez pas à me le faire savoir dans les commentaires 🙂
Sommaire
I. Pourquoi choisir OpenRefine ?
OpenRefine a de nombreux atouts : il est gratuit, open source et tout est stocké en local.
Il faut néanmoins garder à l’esprit qu’il a une performance limitée (de l’ordre de 100 000 lignes max).
II. Présentation du dataset
Pour l’exemple, j’ai choisi une liste de tweets diffusés par les représentants démocrates et républicains américains le 18/05/2018.
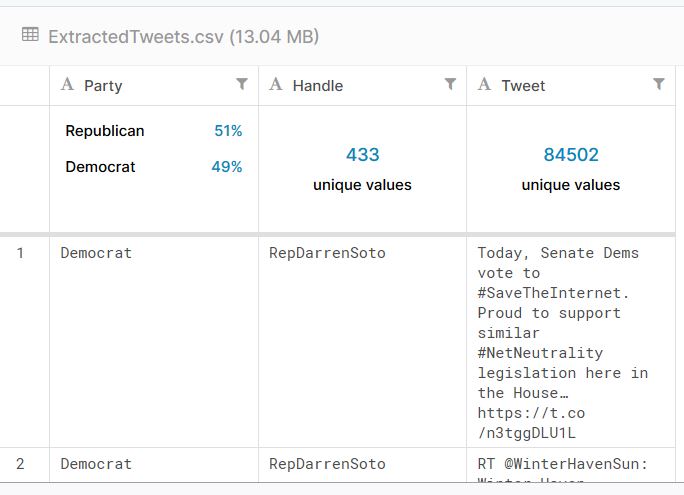
Notre objectif est d’analyser ce dataset afin de déterminer quelles sont les mentions et les hashtags les plus utilisés chez les républicains et les démocrates ce jour-là.
Source du dataset : https://www.kaggle.com/kapastor/democratvsrepublicantweets
III. Démonstration
Nous allons uniquement nous focaliser sur l’aspect technique de l’extraction des données textuelles.
Dans la réalité, pour que ce travail ait du sens n’oubliez pas de vérifier d’où viennent les données (pour détecter des biais éventuels) et de traiter les incohérences ! J’entends par là détecter les valeurs aberrantes et documenter leur traitement (comme leur non prise en compte par exemple).
1. Extraire les données
On va extraire les portions de texte qui nous intéressent (dans notre cas les « mentions » et les « hashtags »).
Par chance, ils sont faciles à identifier, les mentions commencent par « @ » et les hashtags par « # ». De plus, ils ne comportent pas d’espace. On peut donc utiliser une expression régulière pour les isoler.
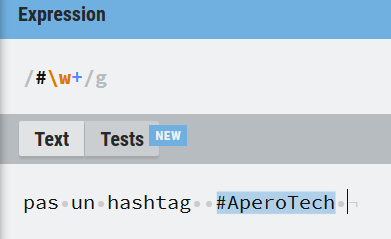
Le site utilisé est https://regexr.com/, les mots qui correspondent à l’expression régulière sont surlignés en bleu. On voit bien que l’hashtag est reconnu ici (pour les mentions, il faut simplement remplacer le caractère ‘#’ par ‘@’).
On va ensuite créer une colonne pour isoler les mentions et une pour isoler les hashtags en se servant des expressions trouvées précédemment :
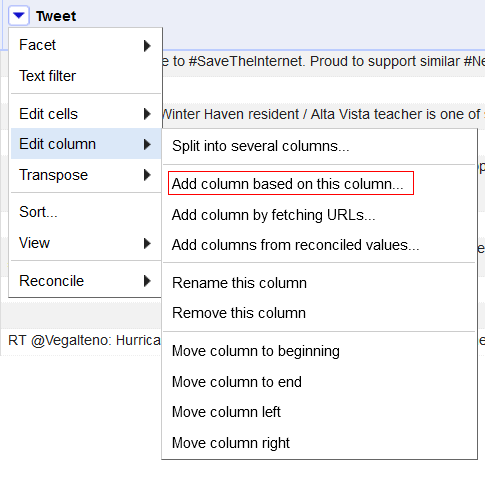
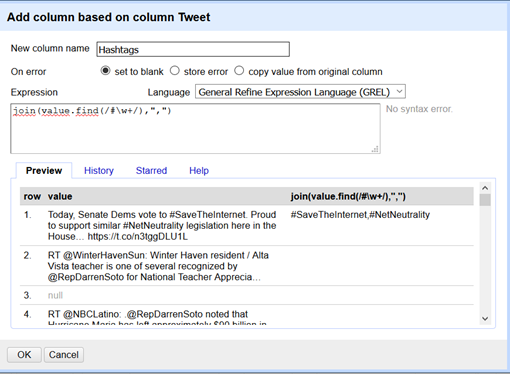
Ici, on a renseigné dans « Expression » :
join(value.find(/#\w+/),",")
Cela signifie littéralement : « met dans la nouvelle colonne tout ce qui correspond à l’expression régulière et sépare-les par une virgule » (important pour la suite).
2. Séparer les colonnes en plusieurs lignes
Nos informations sont bien présentes dans les colonnes, mais elles sont toujours difficiles à analyser.
Pour faciliter cela, on va séparer les informations en plusieurs lignes. Autrement dit, si dans une colonne j’ai deux Hashtags, je vais les séparer en deux lignes distinctes.
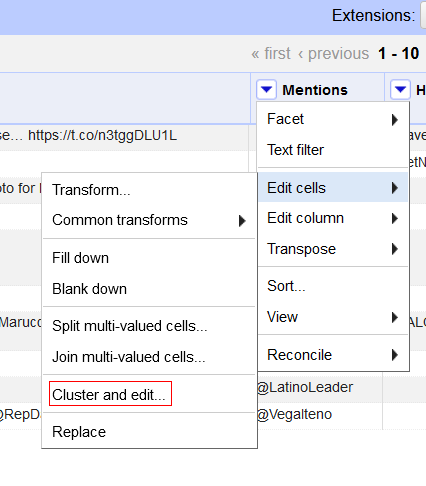
Pour chaque colonne, sélectionnez Edit cells > Split multi-valued cells
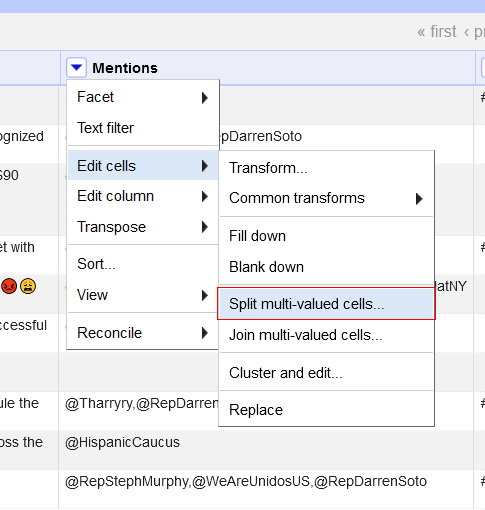
Vous n’aurez plus qu’à cliquer sur « ok ».
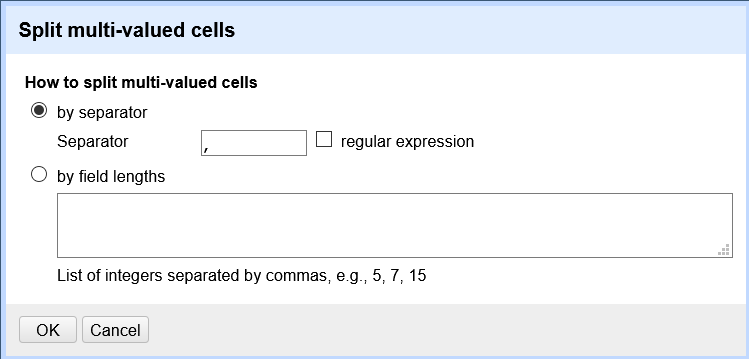
Résultat :
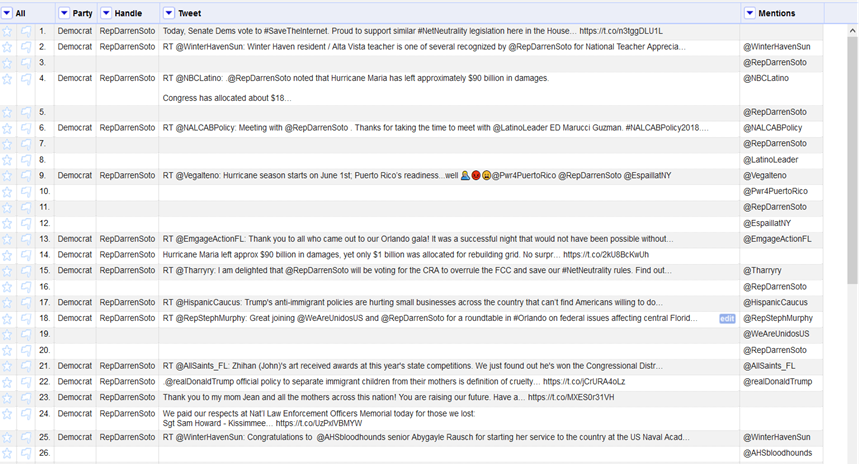
3. Récupérer le parti politique pour chaque ligne
Vous l’avez sûrement remarqué: on voit par exemple ligne 3 sur l’image ci-dessus que le la colonne « Party » est vide. Pour régler ce problème, rien de plus simple: cliquez sur la flèche de « Party » puis « Edit cells » et enfin « Fill down »:
Résultat :
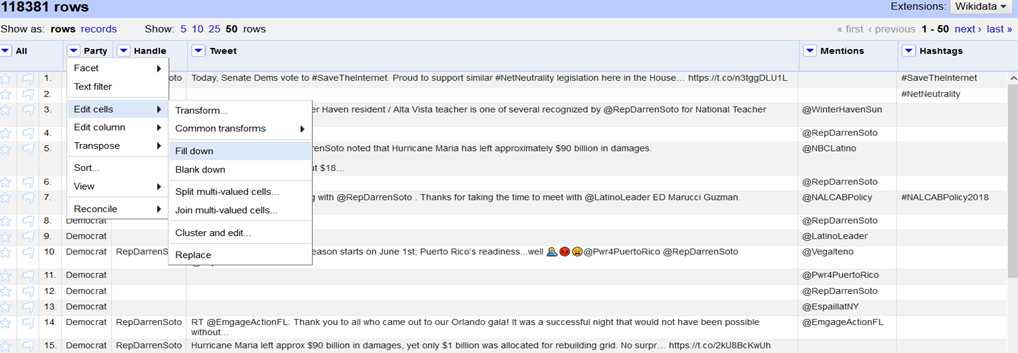
4. Nettoyage des données
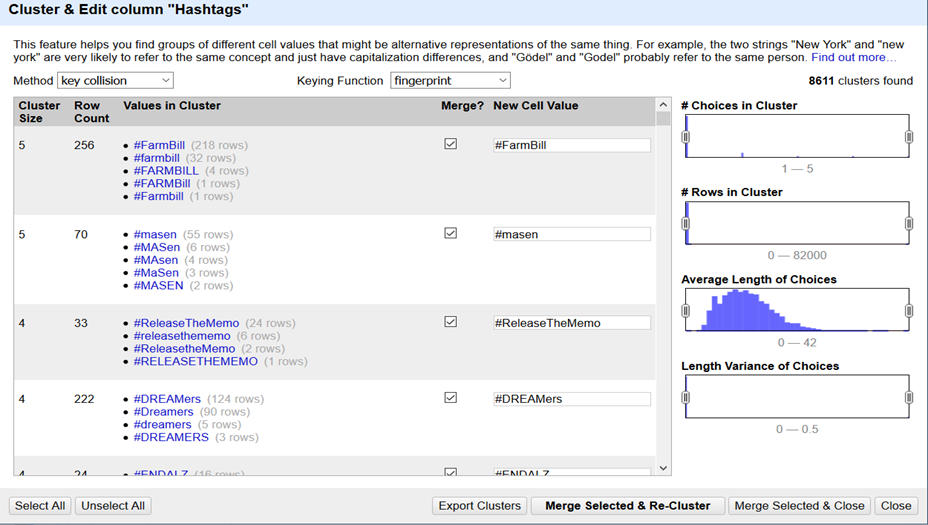
Lors de cette étape il est impératif de nettoyer nos données avant de les exploiter. En effet, de nombreux tweets évoquent le même sujet mais avec des écritures différentes : on peut penser que les hashtags #FarmBill, #FARMBILL #farmbill mentionnent le même sujet, il faut donc les regrouper.
Pour se faire, on va utiliser la « clusterisation« .
Nous avons fait un premier regroupement des valeurs avec l’algorithme : « Key collision » car il a un taux de faux positif relativement faible.
Nous avons ensuite fait un second regroupement avec l’algorithme « Nearest neighboor » en vérifiant une à une manuellement les clusters. En effet, les informations avec des dates différentes sont considérées comme identiques.
5. Exploitation des données
Avec les Facets d’OpenRefine, on peut faire une première analyse :
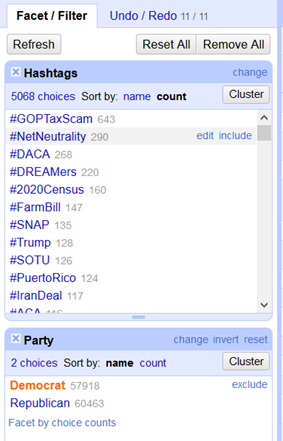
Ici, on voit la liste des hashtags utilisés par les démocrates sur la période : Durant ce laps de temps les démocrates ont tweeté 643 fois le tweet #GOPTaxScam, c’est celui-ci qui a été tweeté le plus de fois.
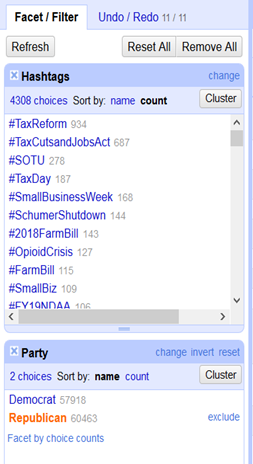
Sur la même période, les républicains ont tweeté #TaxReform 934 fois.
On peut évidemment faire la même analyse sur les mentions :
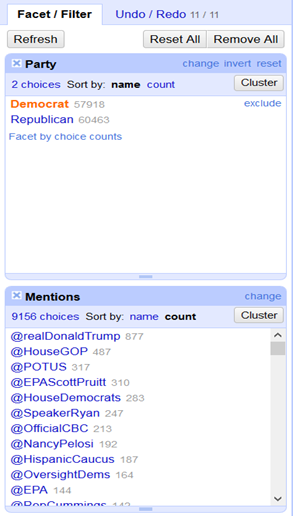
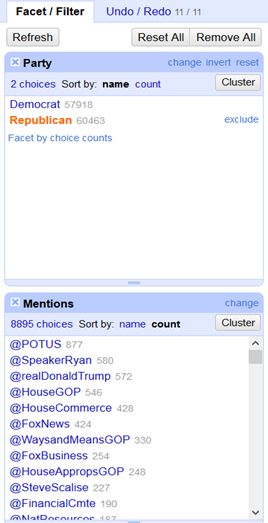
Note: POTUS est un acronyme pour « President Of The United-States » 🙂
6. Export des données
Pour partager les données extraites à des fins d’analyse, il faut les exporter. OpenRefine propose nativement d’exporter les données au format Excel, CSV ou SQL.
Cette étape n’est pas anodine, l’export au format Excel ne peut pas contenir plus de 100 000 lignes et le format CSV a besoin d’un caractère pour délimiter les colonnes (‘,’ ou ‘|’ par exemple). Il faut bien s’assurer que ces caractères ne soient pas présents dans les données.
Nous avons choisi d’exporter les données au format SQL :
Nous les avons ensuite importé dans une base PostgreSQL via pgAdmin:
Enfin, on vérifie que nous pouvons exploiter ces données:
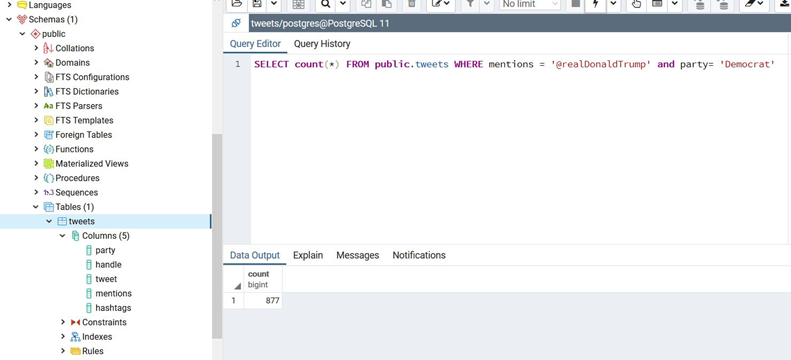
Tout fonctionne comme prévu, nos données sont bien présentes et exploitables dans une base de données ! 🙂
Conclusion
Je vous ai montré ici ma façon de faire pour traiter des données textuelles via OpenRefine. Encore une fois, il s’agissait d’un test du logiciel de ma part et je ne suis pas un expert de cette solution. J’espère simplement que ça permettra de vous aider ou de vous aiguiller dans cette problématique si vous la rencontrez 🙂
Written By